MultiSage: Empowering GCN with Contextualized Multi-Embeddings onWeb-Scale Multipartite Networks
MultiSage: Empowering GCN with Contextualized Multi-Embeddings onWeb-Scale Multipartite Networks
Abstract
Existing GCNs mostly work on homogeneous graphs and consider a single embedding for each node, which do not sufficiently model the multi-facet nature and complex interaction of nodes in real world
networks. Here, author present a contextualized GCN engine by modeling the multipartite networks of target nodes and their intermediate context nodes that specify the contexts of their interactions.
Current Issues and problems
- Nodes are connected in different ways thus close to each other in different ways, which cannot be simultaneously captured by a single embedding.
- How to find proper context?:The real-world networks are often multipartite, it beneficial to model target nodes and context nodes in multipartite networks, where the interactions between the target nodes can be subtly modeled via the help of context nodes.
- How to leverage context?:How to leverage context in massive real-world networks to facilitate
effective and flexible downstream applications.

Preliminaries
Traditional GCN: The output of the $l+1$ th convolutional layer $\textbf{H}^{l+1}$ of GCN is computed as follows
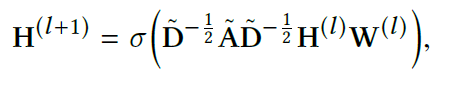
GraphSage: Sample a fixed number of neighbors in each convolution layer and aggregate the neighborhood embedding.
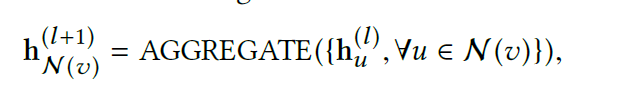
Triplet-wise optimization objective based on max-margin ranking as follows
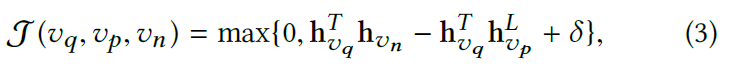
where $\delta$ is a margin parameter, $v_q$ and $v_p$ are the query and positive nodes, $v_n$ is the negative node sampled from $P_n(v_q)$
$\mathcal{T}$:The number of the nodes type in graph
$\mathcal{C}$:Context nodes set
Each $u\in\mathcal{N}_v\subset\mathcal{T}$ of the ego $v\in \mathcal{T}$ is associated with a dominant context node $o \sim(v,u)\in \mathcal{C}$
MultiSage
In this work, Author leverage the heterogeneity of real-world networks by separating nodes into two main types: target nodes and context nodes. Our main focus is to learn embeddings of the target nodes, while using the context nodes to describe the relationship between the target nodes.
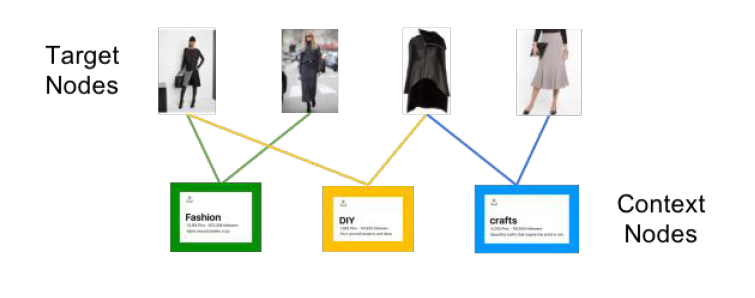
Assumptions:
- minimum domain knowledge is available to separate target nodes from context nodes
- most important interactions among target nodes involve context nodes
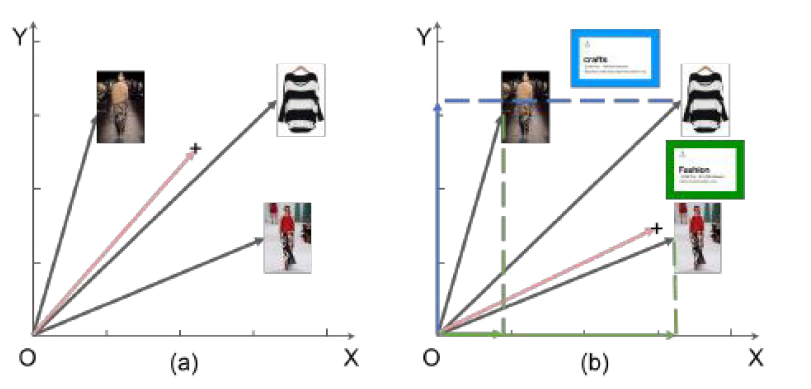
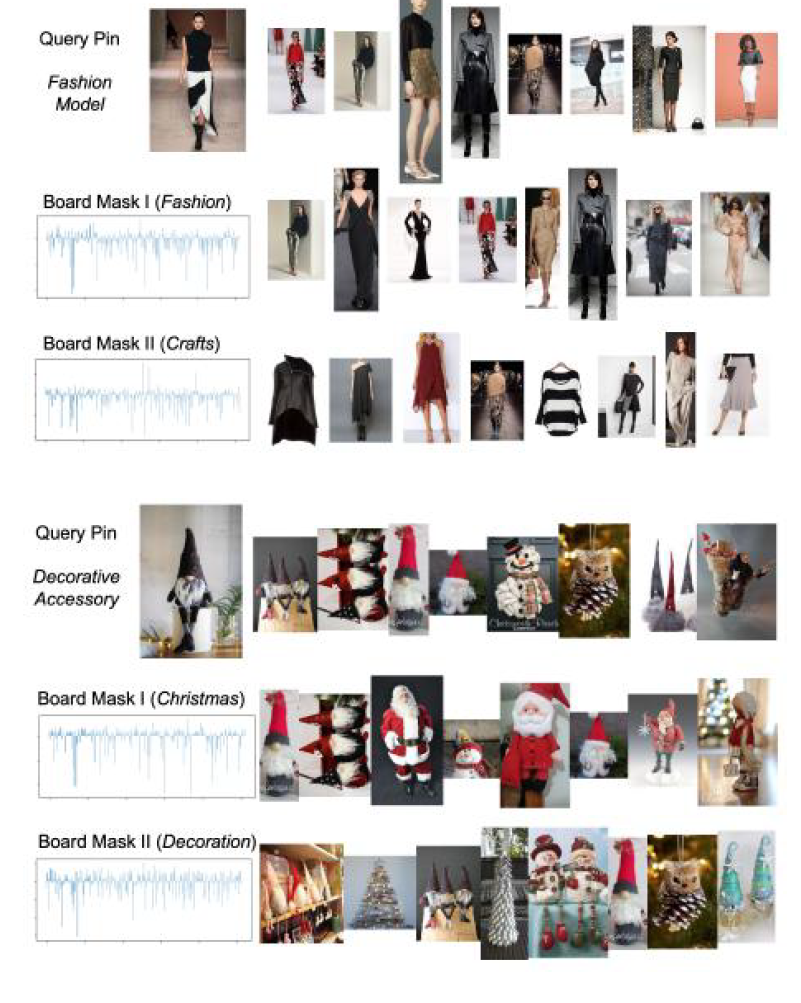
In (a), when three neighbor pins are aggregated through mean pooling, the resulting neighborhood embedding simply lies in the center of the three pins, reflecting the same influence of all neighbors on the ego. In contrast in (b), two neighbor pins are connected via the fashion board while the other one via the crafts board, thus drawing the neighborhood embedding more into the fashion direction. Such contextualization over the target interaction is desirable, since each neighbor is similar to the ego from a particular perspective, and thus should influence the ego embedding more in the corresponding subspace.
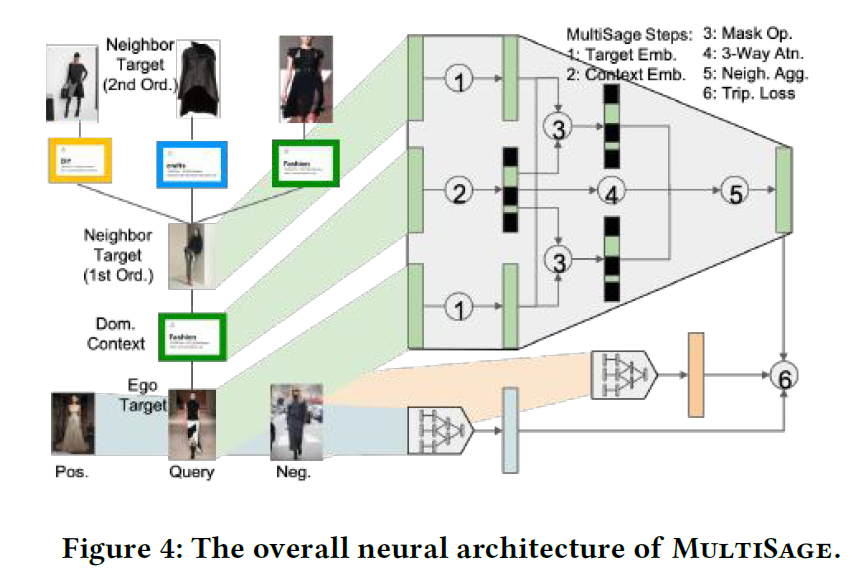
Raw feature transformation
learns to project and transform raw node features via stacked dense neural networks as follows
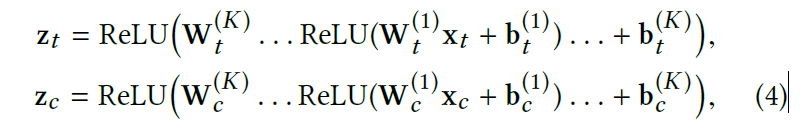
$z_t$ and $z_c$ represent the embeddings of the target and the context nodes, respectively.
Contextual masking
Contextual masking allows us to project different ego-neighbor pairs into various embedding subspaces,
so as to emphasize contextualized interaction among target node pairs regarding particular embedding dimensions at the feature level.
Element-wise multiplying the embedding of the context node $z_c (o)$ onto the embeddings of both ego and neighbor target nodes $z_t (v)$ and $z_t (u)$ as follows
Note that, since the last embedding layer of $z_c$ is ReLU, certain dimensions can be learned to be zero, which effectively “masks out” irrelevant dimensions, so as to project the target embeddings into particular subspaces directly controlled by the context embeddings
Autho also introduce:
where $\odot$ means the concatenation.
Contextual attention
Author design a novel contextual attention mechanism to consider the overall impact of different neighbors of ego at the node level, by jointly computing an attention weight for each ego-context-neighbor triplet $\alpha (v,o,u)=$
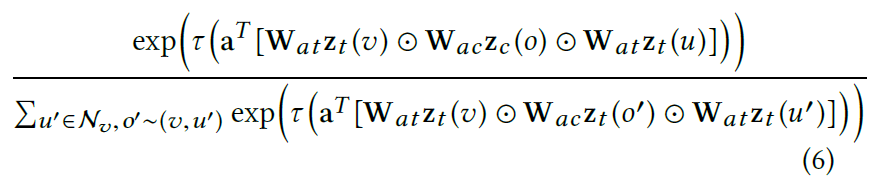
where ${a,W{at},W{ac}}$ are the learnable attention parameters. $\tau$ is the LeakyReLU activation function.
To further improve the capacity and stability, we exploit multi-head attention to compute the aggregated contextualized embedding as follows:
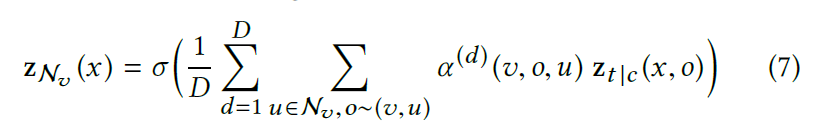
Training objective
Author directly add the contextualized ego embedding $z{N_v} (v)$ and neighbor embedding $z{N_v} (u) $as
the final MultiSage embedding $h(v)$.
Training loss:
sampling positive neighbor and negative neighbor $v_p,v_n$

这个加法是合理的,如果u,v是邻居,则$h_u$=$h_v$,那么乘积就会很大,如果不是邻居,则$h_u$ 不等于$h_v$乘积会小,则loss是会变大的。
Contextualized random walk
由于每个游走序列会有多个中间节点,但是其实只是有一些中间节点是不重要的,于是对每个ego-target node pair只保留最重要的中间节点。

vis[v]:记录节点访问次数
ctx[v]:记录中间节点和target节点
dom[v]:记录不同中间节点的重要性
line 7: 对所有的访问过的context node 记录增加
line8-15:运行多次random walk,记录出现target node情况下,出现最多的contex node。
Experiment
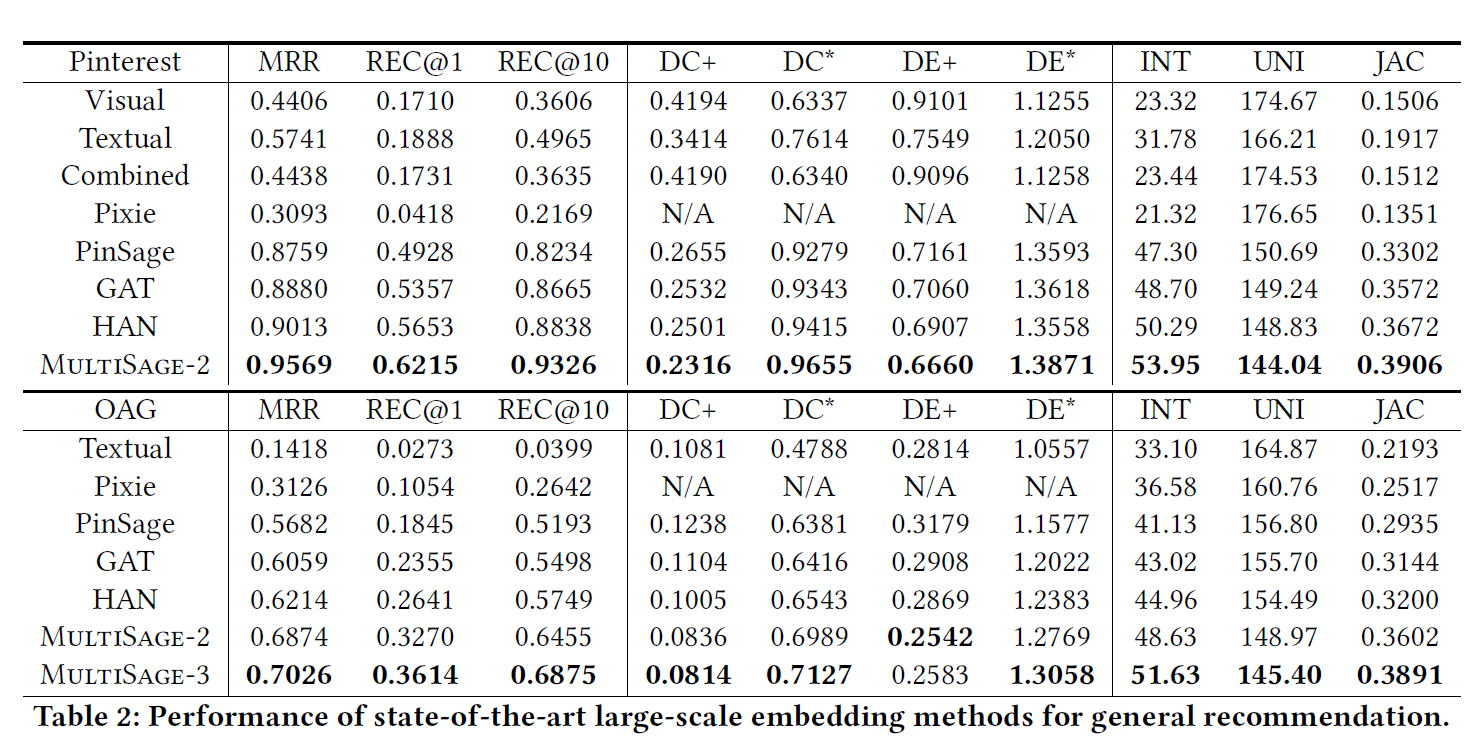

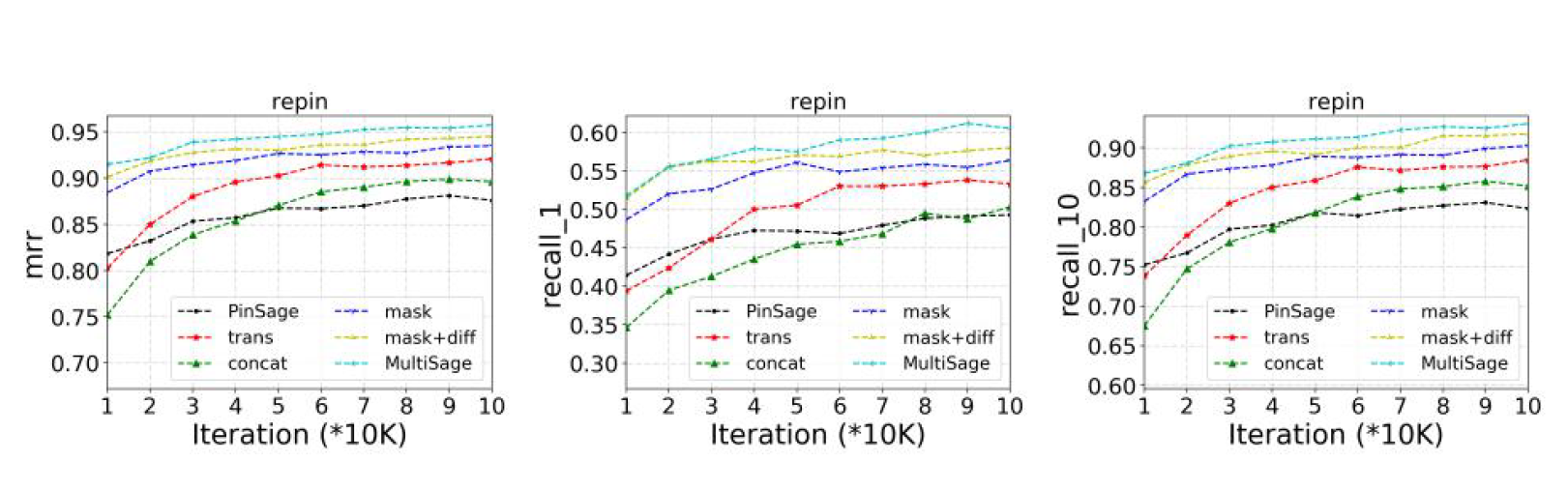
可以使用mask去获取不同的候选商品,因为mask会剔除一些不同的特征,可以让目标映射到不同的子