MultiImport: Inferring Node Importance in a Knowledge Graph from Multiple Input Signals
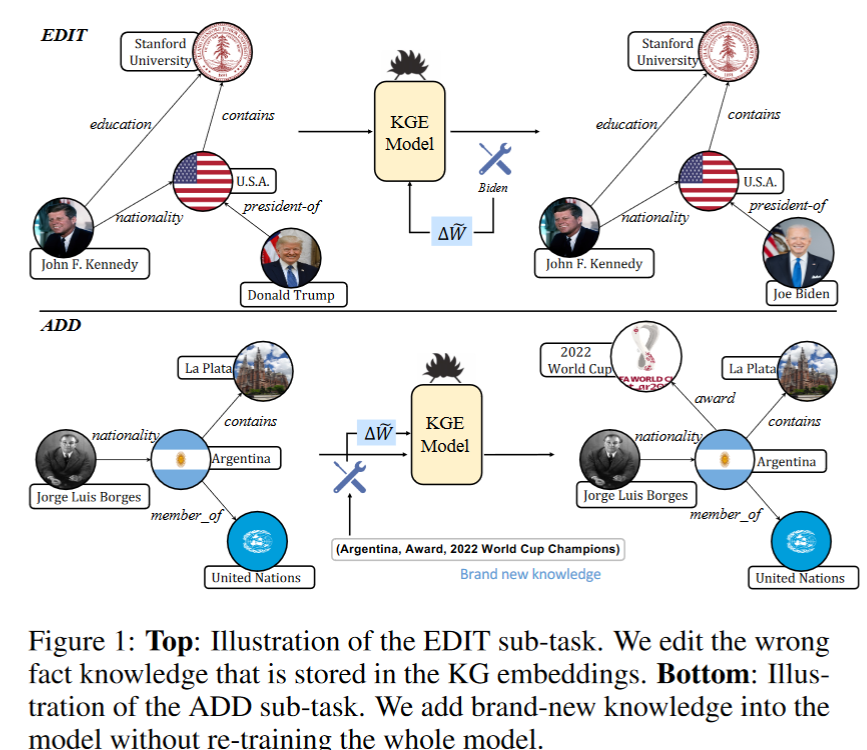
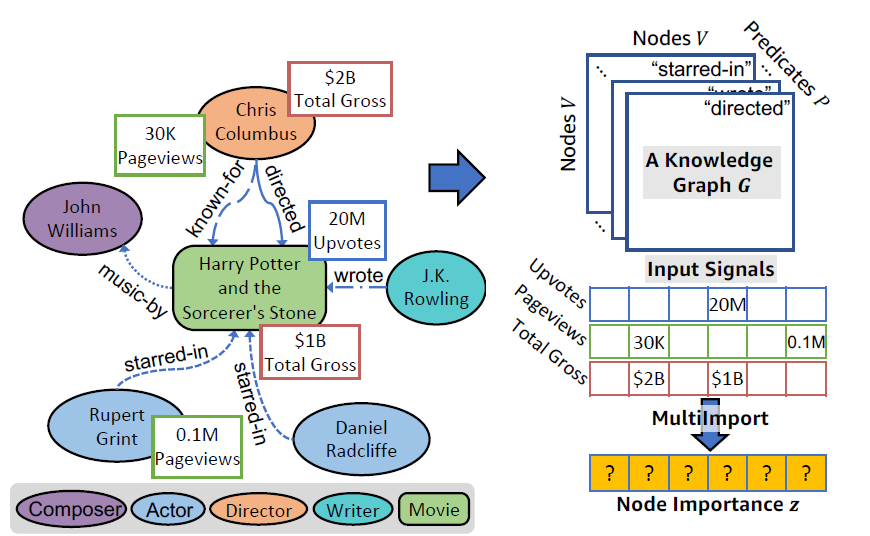
简介:对一个拥有多种节点重要性的图谱来说,如何去正确的估计他们每个节点重要性是一个很巨大的挑战。其中一个重要的问题就是如何从多种的不同的输入中有效的提取信息。针对这个问题,作者提出了一种隐向量模型,他可以从不同的信号中捕获节点的重要性。 以上图为例,针对一个电影的知识图谱来说,存在不同的种类的的节点,同时每个节点的信息可能拥有不同的属性。以不同的属性作为评价指标,其每个节点的重要性也是不一样的,并且不是每个节点都有全部的属性。这就导致了两个问题: 节点的重要性以不同的属性作为评价,所得到的结果是不一样的。 可能会存在空属性的情况,导致节点在那个属性下无法评价重要性。 作者希望对所有节点学习到一个通用的属性重要性$z$,这样作者就可以对图中所有的节点进行一个统一的重要性表达。 符号定义Node Feature$X\in \mathbb{R}^{|V|\times F}$ Node Importance$z\in \mathbb{R}_{\geq 0}$,是一个非负的实数,代表图中每个节点的重要性。 Input Signal$V’ \to \mathbb{R}_{\geq 0}...
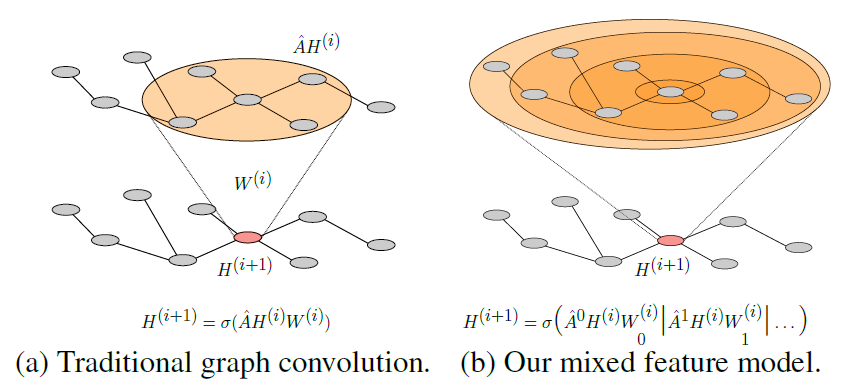
MixHop:Higher-Order Graph Convolutional Architectures via Sparsified Neighborhood Mixing
简述现有的基于半监督的图神经网络算法,不能很好的学习到不同跳的邻居特征。本文提出了一种可以重复的表达不同距离的邻居用户特征的算法。 原始GCN不同层卷积都用相同的权重,不能捕获不同层的信息差异性,本文证明了对不同层采用不同的信息传递权重能捕获不同层之间的信息差异性。 贡献 提出了Delta Operators,并证明了传统的GCN模型没有能学到这样的表达 提出了MixHop,通过利用多次邻接矩阵,作者证明MixHop能够学习到更广泛的邻居特征,同时也不会增加模型的内存。 问题 传统GNN一次只能卷积一次邻居 在降低邻接矩阵求特征值的复杂度之后丢失了一些信息 假设 模型 Delta Operation 这是一个在不同距离的节点特征之间收集特征的操作。一个模型能够学习到两跳的信息的前提是其存在一组参数和一个injective mapping $f$,可以使得网络的输出可以给定任何邻接矩阵$A$和特征$X$。 MixHop Graph Convolution Layer 和传统GCN重复乘以A不同,本文在一次操作里乘多次A,一次性获得多跳的信息。并且和传统GCN的每层权重矩阵W相...

生物信息学复习提纲
简介本文是本人基于哈尔滨工业大学生物信息学整个课程的复习提纲 绪论组学:生物学中对某些生物分子的整个集合进行的系统性研究 组学基本法则:获取大样本-高通量侧学-数据分析-结果注释:生物验证 基因数据库:SRA数据库:手机全世界的基因组原始测序数据 GenBank数据库:1983年起,收集全世界公开发表的DNA序列 GEO数据库:收集基因表达谱数据,收集超过9.1w数据集 生物信息学:是研究生物数据管理、存储、检索、分析、挖掘、可视化的算法与系统,实现对生物数据的理解和利用的一个多学科交叉领域。 生物数据和数据库DNA: 一串由ACGT组成的字符串 双链结构 RNA: 一串由ACGU组成的字符串 蛋白质:… 生命: 有生命和无生命 有生命:可以移动、繁殖、生长、进食,和外界进行物质交换 无生命:无法和外界进行物质交换(除了种子,病毒) 有生命和无生命都符合相同的物理和化学规则 蛋白质和核酸: 蛋白质: 决定生物的性状 核酸: 编码蛋白质 传递遗传信息 蛋白质: 一级结构:组成蛋白质的多肽链的线性氨基酸序列。 二级结构:依靠不同氨基酸C=O和N-H基...

数据库复习提纲
简介本文是本人基于哈尔滨工业大学数据库系统整个课程的总结和复习提纲 绪论 2020年6月4日 9:15 数据库定义:· 相互关联关系的数据的集合 Table:· Table中描述了一批互有关联关系的数据。 数据库构成:· 数据库(DB):Database:一组关联关系数据集合 · 数据库管理系统(DBMS):Database management system:管理数据的软件 · 数据库应用(DBAP):Data base Application:完成某一功能的应用 · 数据库管理员(DBA):Database Administrator:管理数据库的人 · 计算机基本系统 实例化和抽象化:把数据库的构成实例化成各个具体的应用。 数据库管理系统的功能:(DBAP)· 数据库定义:定义数据库中Table的名称、标题、标题内属性和属性值的要求 o DBMS提供DDL语言给用户定义数据库 o 用户使用DDL创建表格式 o DBMS解析DDL并执行 · 数据库执行:对表中数据库进行增删查改等操作 · ...

Finally Meet My Girl
从初二到大四,八年的等待,曾经因为胆小而错过的那双手终于被我牵上了,从今往后再也不会放开。

Cant stop thinking about u
第一次心里一直想着一个人
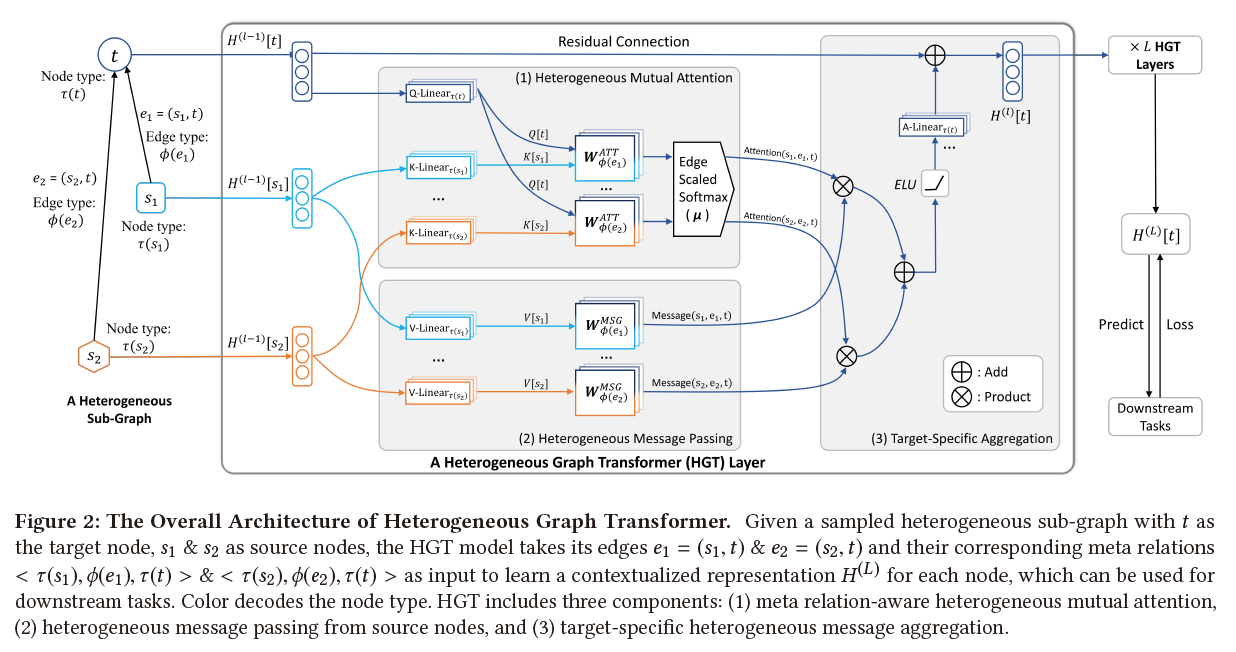
Heterogeneous Graph Transformer
Abstract在传统的GNN中,所有的节点和边都属于一个种类,导致一些传统的GNN手段没有办法适应异构图的结构。在这篇文章中作者提出了一种基于异构图的transformer结构,用来生成不同种类的节点、边的attention值。为了解决任意时间的动态图,作者提出了一个 relative temporal encoding technique。同时为了解决大量的 图数据库,作者提出了一种基于mini-batch的图采样算法,来在图上进行高效的训练。 Current Problem 基于meta-path的方法需要专家知识 简单的假设所有的边和节点都有相同的特征表示空间 对不同的边采用了不同的权重矩阵,有大量的种类的边和节点,同时不同种类的边和节点出现的次数也不一样,对出现数量较少的边可能不是很好建模 忽视了图的动态性 Contribution 针对Heterogeneous Graph 边和点的种类数目过多的问题,作者采用对Meta Relation建模的,方式,通过起点和终点,以及边的种类来对一个meta relation建模。这样可以使用较少的参数。 通过神经网络结构来捕获...
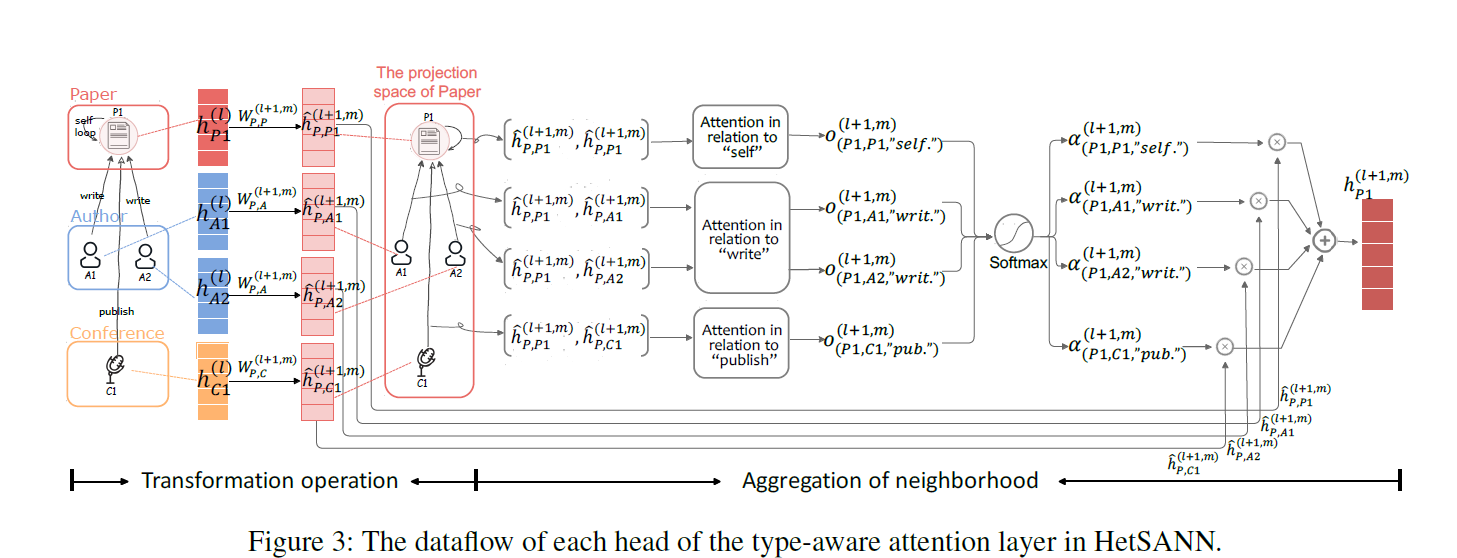
An Attention-based Graph Neural Network for Heterogeneous Structural Learning
Introduction作者提出了一种在异构图上进行GNN图卷积的方式,主要是利用了对不同类型的边设定一个独有的参数$W$转到一个相同的空间,同时还用了多头的和边有关的attention机制来进行邻居信息的聚合。 ApproachTAL层: 根据节点两个节点之间种类,用一个对应的线性变换矩阵$W$,把邻居的embedding转换到目标的空间。 邻居聚合: 对不同的边的做了一个各自的线性变化$a_r$ 然后通过一个attention,在对邻居进行聚合。 然后通过一个multi-head机制,同时使用多个attention参数,并把结果拼接起来,作为一个节点最后的表达。 并在多层卷积的过程中加入了残差层 Extension 针对边和回边的问题,作者希望attention的值应该是正好相反的。 环理论,一个j->j的转换应该等于j->i, i->i, i->j这两个应该是相等的。所以变换矩阵应该有如下的性质。 i->i的矩阵是有方向的,所以需要求一个逆矩阵,这个工作很耗时,所以作者用train的方法来实现求得该逆矩...
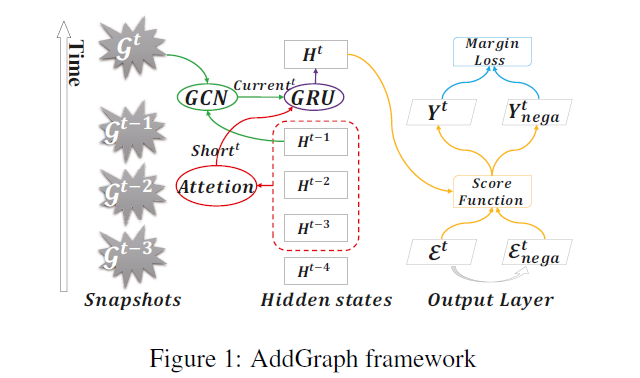
AddGraph, Anomaly Detection in Dynamic Graph Using Attention-based Temporal GCN
Introduction:异常检测常见的领域就是在电商。比如异常的用户会通过对目标商品以及流行商品做大量的相同操作,比如同时点击目标商品和流行商品,从而增加了目标商品和流行商品的相似性。从而在推荐系统里增加了评分。这篇文章是针对动态图的异常检测,异常检测 对于下流任务很重要。 和传统的图方法相比,GCN能够自动的传播从邻居节点的信息,从而扩散节点的异常概率。GCN在异常检测方面主要的问题在于没有考虑时间特征(不能在动态图上忽略的)目前的一些工作 CAD [Sricharan and Das, 2014] and Netwalk [Yu et al., 2018] 把 graph embedding方法应用到动态图,但是不能 捕捉节点的 “长期模式”和“短期模式”。 主要贡献: 提出AddGraph框架,提出一个attention-based GRU的GCN框架,获得短时和长时特征。 受到知识图谱的启发,引入一个negative sampling 和margin loss来检测异常边 Problem Definition:$T$是最大的时间步长,图的集合${G^...
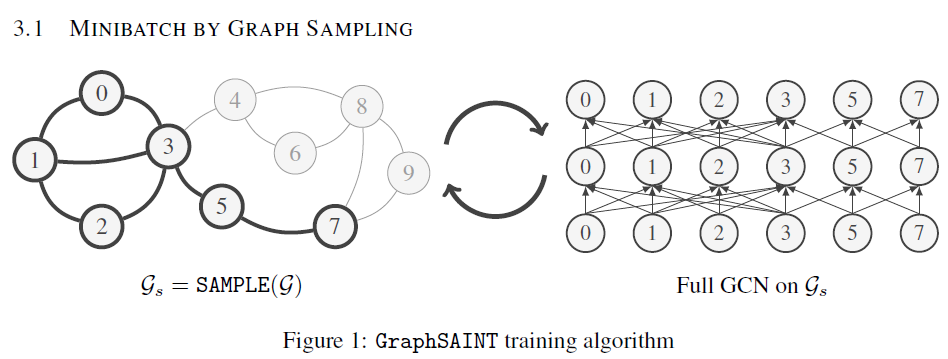
GraphSAINT,一种无偏的图采样方法
背景在现在的图卷积中,由于图的大小可能非常大,传统的在全图上进行图卷积的操作往往是不现实的。因此往往采用了图采样的方法。图采样大致会分为:Layer Sampling 和 Graph Sampling两种。但是这两种方法都存在着一些问题。 Layer Sampling: 1. 邻居爆炸:在矩阵采样多层时,假设每层采样n个邻居,则会导致$n^2$级别的节点扩充速度。 2. 领接矩阵稀疏:在矩阵采样的过程中,会导致邻接矩阵稀疏化,丢失一些本来存在的边。 3. 时间耗费高:每一层卷积都要采样,这就导致计算的时间耗费。 Graph Sampling: Graph Sampling是一种相对好的采样方法,可以在preprocess阶段提前采样图,并且可以进行mini batch的加速。但是这样的采样往往会丢失一些信息。 本文为了解决以上问题,提出了一种在图上进行Graph Sampling的相对较好的方法。 方法在普通的Layer采样过程中,我们希望采样之后产生的偏差最小。这个偏差可以由如下的公式得出。 我们希望如下的偏差最小,经过一系列复制的推导,在$P_e$等于如下值的时候,偏...
最新文章